10 essential steps to ensure enterprise data security
This blog lists ten steps a corporate must take to ensure enterprise data security.

Get fresh insights, pro tips, and thought starters–only the best of posts for you.

In the Enterprise RFP process, while every vendor can answer “Is your cloud secure?”, only a few can answer the more critical question, “What happens during a minor cloud failure?” At a scale of 200,000 endpoints, a localized service failure shouldn’t trigger a global operational shutdown. But for a CIO managing a global fleet, 99.9% uptime is a marketing metric, not a resilience strategy. True operational trust is built on the technical specifics of Disaster Recovery—RTO (Recovery Time Objective) and RPO (Recovery Point Objective)—the metrics that determine exactly how fast you regain control and how much data you can afford to lose.
Most UEM vendors hide these numbers behind generic SLAs. At Hexnode, we believe in “Resilience by Design”. This engineering deep dive explains how Hexnode’s architecture is built to meet the rigorous RTO/RPO demands of the modern enterprise.
In cloud architecture, 100% uptime is a mathematical impossibility due to the realities of global network fluctuations and hardware maintenance. Because perfection doesn’t exist, 99.9% has become the standard industry benchmark. However, a 99.9% uptime SLA allows for 8.76 hours of downtime per year. And, when you manage a global fleet, those 8 hours of allowed downtime translates into catastrophic operational failures:
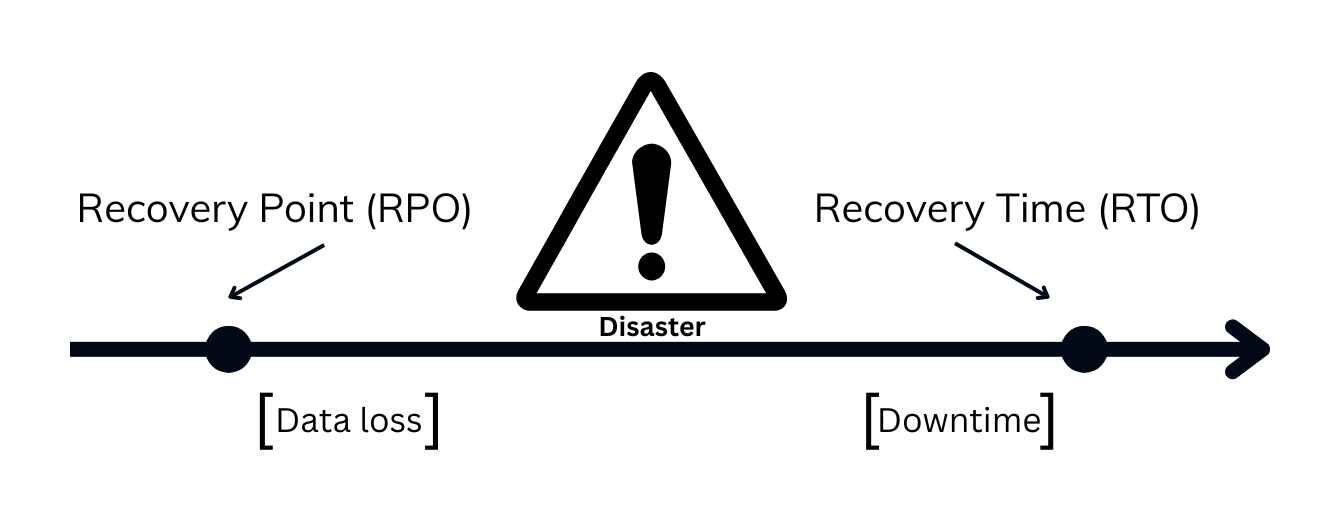
Unlike a static database, a UEM platform has two distinct recovery vectors: Data and Control.
In endpoint management, data loss isn’t just a missing record. It’s a missing security action. If an admin triggers a “Device Wipe” seconds before a failover, that command must persist and should not simply disappear.
Typically, Tier 1 critical apps usually require an RPO of < 15 minutes. However, at Hexnode, we exceed this benchmark by utilizing Hot Standby across different availability zones. Additionally, we utilize Amazon Relational Database Service (RDS) to manage all critical CRUD (Create, Read, Update, Delete) operations.
Unlike legacy systems that rely on batch-processing, Hexnode logs every policy change, enrollment, and compliance in real-time. To ensure absolute data persistence, we maintain synchronous database replication. This is backed by expert teams that identify and remediate anomalies before they impact your fleet’s uptime.
As a result, for enterprise dedicated environments, we achieve a Near-Zero RPO. This ensures that your most recent, mission-critical security commands—like a device wipe or a password reset—remain intact and executable the moment the system is recovered.
In the UEM world, there is a massive difference between a Server RTO (when the dashboard is back online) and a Control RTO (when the devices actually start listening again). If your dashboard is up but your devices aren’t responding, you haven’t truly recovered.
Typically, Tier 1 Systems require recovery within 1 to 4 hours. However, the industry faces a major technical bottleneck: The Polling Gap. Most competitors rely on architectures where devices check in only every 4 to 8 hours. The real-world value of a low RTO becomes clear during mass-remediation events, such as the CrowdStrike outage. When a bad patch or a faulty configuration bricks thousands of devices, every second of the polling gap equates to thousands of dollars in lost productivity. Even if their server recovers in 10 minutes, your fleet remains dark for hours until the next scheduled check-in.
Thereby, Hexnode eliminates the blind spot that follows a cloud outage. While other vendors are waiting for their devices to wake up, Hexnode admins are already executing remediation scripts and securing their endpoints.
Another risk to your Disaster Recovery RTO and RPO is not just the initial crash. It’s the moments when the lights come back on.
When a UEM platform recovers, 200,000+ devices immediately attempt to check in simultaneously. This creates a massive, DDoS-style traffic spike known as the “Thundering Herd.” Without proper engineering, this surge crashes legacy MDM servers, turning a 10-minute outage into a 10-hour recovery cycle.

Master the evolution of endpoint management. Learn how to implement a unified management framework across your entire global fleet.
Get the white paperFor an Enterprise Architect, disaster recovery isn’t about hoping a server never fails; it’s about ensuring that when it does, the impact is invisible to the business. By moving beyond the 99.9% baseline and investing in a persistent, synchronous architecture, Hexnode ensures your fleet remains under your control—no matter what happens in the cloud.
1. What is a good RTO/RPO for Enterprise MDM?
A: For mission-critical Enterprise MDM, a “Good” RTO (Recovery Time Objective) is under 4 hours, and a “Good” RPO (Recovery Point Objective) is under 1 hour. Hexnode achieves this via Hot Standby and persistent WebSocket connections, ensuring immediate control recovery compared to legacy polling architectures.
2. How does MDM failover affect audit compliance (SOC 2)?
A: Hexnode uses synchronous transaction logging across availability zones. This ensures that even during a failover event, the any change or update made remains intact and immutable, ensuring continuous compliance with SOC 2 Type II and ISO 27001 standards without data gaps.
3. Can Hexnode execute remote wipes during a partial cloud outage?
A: Yes. Critical security commands like “Remote Wipe” or “Device Lock” are routed through the nearest available healthy region. Persistent WebSocket connections allow these commands to execute in near real-time even if the primary dashboard region is experiencing latency.
Don't let your infrastructure collapse during a recovery event. Experience the resilience of Hexnode’s capabilities.Build a Disaster-Ready Fleet Today



