Real-Time MDM Recovery: Surviving the Bad Patch
This guide explains the engineering difference between “Managing” a fleet and “Saving” one.

Get fresh insights, pro tips, and thought starters–only the best of posts for you.

In the world of Enterprise IT, there is a button that every administrator fears.
It isn’t “Wipe.” Neither is it “Lock.” It is the button that says “Deploy to All.”
When you manage a fleet of 500 devices, clicking that button is trivial. But when you manage 50,000 endpoints, and the payload is a 1GB critical application update (like a CAD suite or a massive OS patch), the physics of the internet change. This is the ultimate stress test for any Scalable MDM Architecture.
50,000 devices × 1 GB = 50 Terabytes of data.
If you try to push 50 Terabytes of data through a standard server stack in 20 minutes, you are effectively launching a DDoS attack against your own infrastructure. Firewalls melt. Databases lock up. The deployment fails.
Yet, last month, a Hexnode enterprise customer did exactly this. They pushed a 1.2GB proprietary app container to 50,000 distributed kiosks. The rollout completed in 18 minutes. No crashes. No downtime.
This didn’t happen by magic. It happened because we engineered the Hexnode’s architecture to survive the “Thundering Herd.”
This is a look under the hood at the WebSocket Architecture, CDN Strategy, and Flow Control Algorithms that make massive scale possible.
To understand why this feat is difficult, you have to look at how legacy Mobile Device Management (MDM) platforms were built in the 2010s.
Most competitors lack a truly Scalable MDM Architecture because they rely on HTTP Polling.
We realized early on that Polling is the enemy of Scale.
To solve this, we engineered a four-layer architecture that separates the command, the data, the traffic flow, and the error handling.
The first step to pushing 1GB is not sending the file. It’s sending the command to download the file.
Hexnode replaces polling with Persistent WebSocket Connections.
The Deployment Event: When the admin clicked “Deploy,” our core engine didn’t wait. It pushed a 2KB JSON payload down 50,000 open pipes instantly.
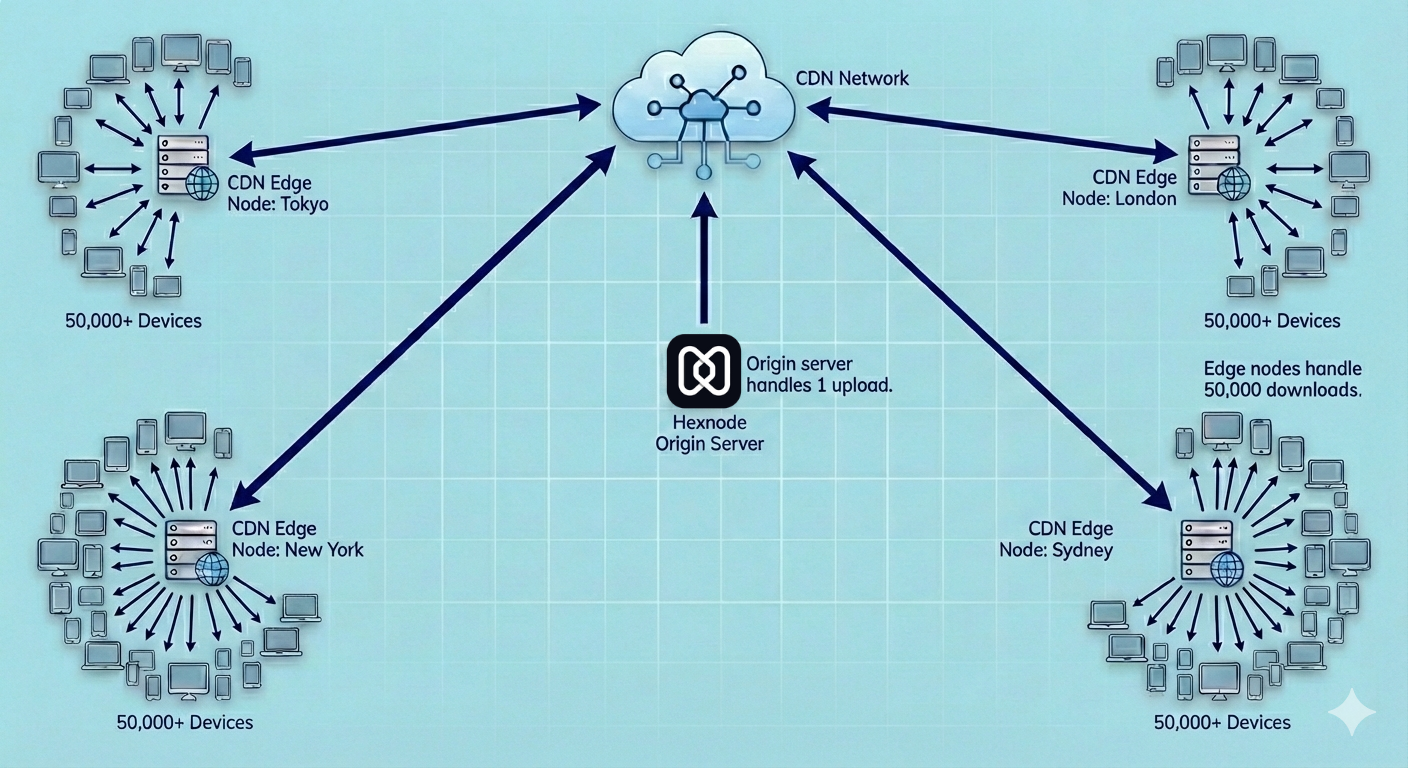
Here is the secret to handling 50 Terabytes of traffic: The Hexnode Server never touches the file.
In a Scalable MDM Architecture, decoupling the control plane from the data plane is essential. If 50,000 devices tried to download 1GB from our primary AWS S3 bucket, the egress costs would be astronomical, and the throughput would collapse.
Instead, we utilize a Global Content Delivery Network (CDN) strategy (leveraging partners like Cloudflare and CloudFront).
The Workflow:
The Result: The “Thundering Herd” of traffic never hits the Hexnode Core. It is absorbed by the massive bandwidth capacity of the global internet backbone. This is how we achieve 40+ Gbps throughput without our dashboard even flickering.
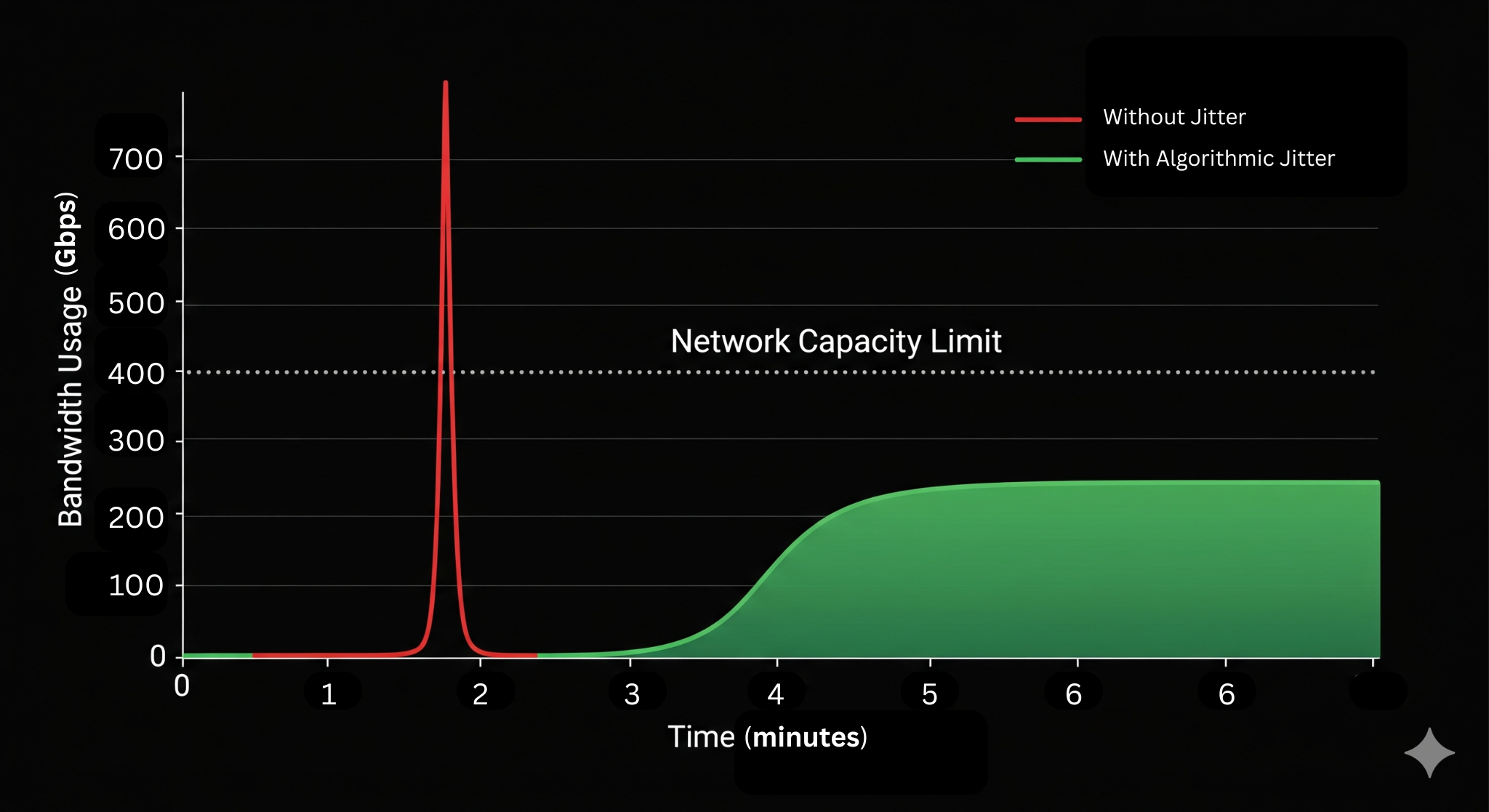
Even with a CDN, if 50,000 devices start downloading at the exact same millisecond (T=0), local networks will collapse.
To solve this, Hexnode implements Algorithmic Jitter (Randomized Back-off).
We don’t tell the fleet: “Download Now.” We tell the fleet: “Download within the next 10 minutes.”
Python Pseudocode
|
1 2 3 4 5 |
#Simplified Logic on Device Agent download_window = 600 #seconds random_delay = random.randint(0, download_window) wait(random_delay) start_download() |
By introducing this randomized delay at the agent level, we smooth the traffic curve. Instead of a vertical spike (which breaks networks), we create a manageable “plateau” of bandwidth usage.
In a 1GB transfer, failures are statistically guaranteed. A user will close their laptop lid. A Wi-Fi connection will drop.
If the download fails at 99%, and the device restarts from 0%, you have wasted bandwidth and time.
The Hexnode Agent Engine:
This ensures that even on flaky 4G/5G connections, the deployment eventually succeeds without admin intervention.
Why should a CISO or Enterprise Architect care about WebSockets and CDNs?
Because Architecture determines Reliability.
When you are evaluating UEM vendors, don’t just ask “Can you deploy apps?” Ask them:
If they can’t answer these questions with engineering specifics, they aren’t ready for your scale.
We share these details not to brag, but to offer Transparency. We want you to trust Hexnode not because of our marketing, but because of our math.
As apps get larger (AR/VR content, AI models, high-res video), the “1GB Update” will soon be the “10GB Update.”
Hexnode is built for that future. By investing in a Scalable MDM Architecture, we ensure our infrastructure is elastic, our agents are intelligent, and our pipes are infinite. Whether you have 50 devices or 500,000, the experience is the same: Click. Deploy. Done.
Challenge us with your biggest deployment. Scale without the fail. Start your deployment now.
Sign Up TodayQ: How does Hexnode handle massive app deployments without crashing the network?
A: Hexnode uses a combination of Global CDNs (Content Delivery Networks) to offload bandwidth and Algorithmic Jitter (randomized delays) on the agent side. This prevents network congestion (the “Thundering Herd” problem) by spreading the download requests over a set time window rather than executing them all at the exact same millisecond.
Q: What is the advantage of WebSockets over Polling in MDM?
A: In a scalable MDM architecture, WebSockets allow for Real-Time communication. Unlike Polling, where the server has to wait for the device to check in (causing hours of delay), WebSockets maintain an open connection. This allows Hexnode to push commands (like “Lock” or “Deploy”) to 50,000 devices instantly with minimal server overhead.
Q: Does Hexnode support resume for failed downloads?
A: Yes. The Hexnode Agent supports Chunked Downloading and Checkpointing. If a large file download (e.g., 1GB) is interrupted due to network failure, the agent resumes from the last successful chunk rather than restarting from zero, saving bandwidth and ensuring deployment success.



